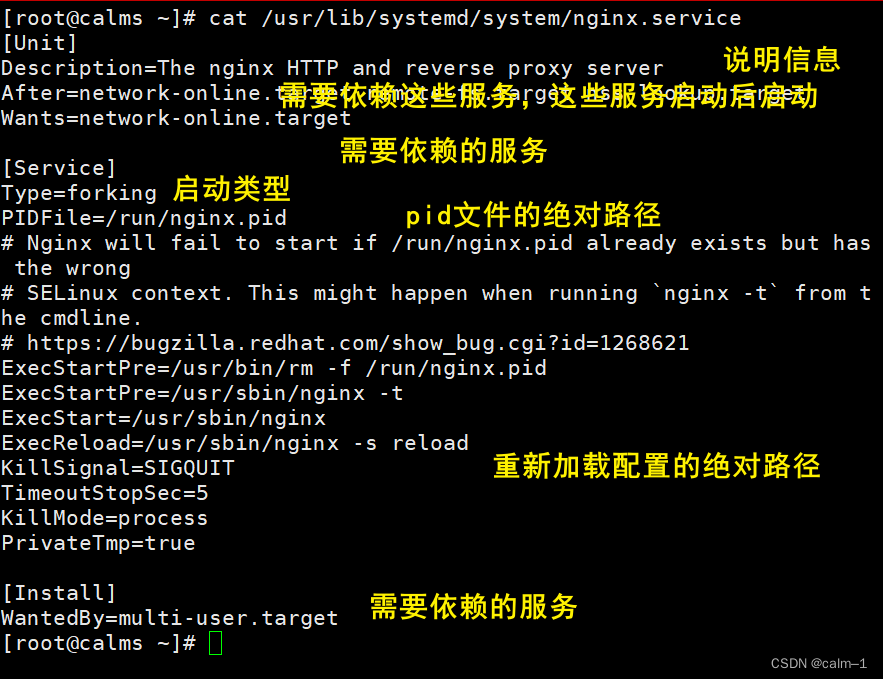
Language Models are Few-Shot Learners
B 部分
回顾一下第一代 GPT-1 :
- 设计思路是 “海量无标记文本进行无监督预训练+少量有标签文本有监督微调” 范式;
- 模型架构是基于 Transformer 的叠加解码器(掩码自注意力机制、残差、Layernorm);
- 下游各种具体任务的适应是通过在模型架构的输出后增加线性权重 W y W_{y} Wy 实现,且微调过程解码器架构也会进行参数微调,迁移的解码器模块越多效果越好;
- 针对不同具体任务对应的数据集采用遍历式方法将数据集增加若干 token 作为输入;
- 微调过程考虑到文本数据集较大时会额外增加预训练型的损失函数;
- 字节对编码。
回顾一下第二代 GPT-2 :
- 背景:“预训练+微调范式” 、 “无监督训练后的模型直接用于特定任务中也具有一定程度的表现” 以及 “多任务学习在 NLP 中存在数据集难以快速制作” 问题;
- 设计思路:使用更大的模型容量(网络参数)以及更大的数据集(网页级别的参数),在输入特定任务的文本前言下(将描述任务的文本输入至模型中)实现 zero-shot 的多任务自然语言任务处理能力;
- 模型架构:基于 GPT-1 的改进(Layernorm、初始化、词汇表数量以及上下文长度);
- 预训练数据集:作者自己制作的 WebText 数据集,经过网页爬取,并经过一些工具进行处理;
- 使用改进的 BPE 用于输入表征;
- (我觉得有意义的)进行了数据集重叠性分析,以验证预训练的模型是 “记忆” 还是 “真的生成” 。
回顾一下第三代 GPT-3 :
- 背景:基于第二代模型的经验 “大容量模型在大规模文本数据集下进行无监督语言模型损失函数式的预训练可以提升各个下游任务的 zero-shot 效果” ,但是在第二代模型的实验中发现 “非常纯粹的 zero-shot” 并非带来超越 SOTA 的效果(甚至在部分任务中达不到 baseline 成绩)。
- 设计思路:沿用第二代模型的经验,且在当时已经有模型放缩定律的初步结论。GPT-3 更看重放缩定律,设计出更大参数体量的模型(1750亿参数的 GPT-3 模型)并采用更多的网页数据集进行无监督训练。在下游任务中,忽视 zero-shot 效果,而是强调在任务描述的提示中嵌入 one/few/2…32-shot 任务相关的示例信息,并将提示好的模型与进行参数改变的微调模型进行对比。
- 模型架构:使用与 GPT-2 相同的模型和架构,包括其中描述的调整模型初始化、预归一化和可逆标记化,不同之处在于 GPT-3 使用了交替的密集和局部带状稀疏注意模式。设置多种不同参数体量的版本,用以验证放缩定律。
- 预训练数据集:基于高质量的参考语料库的相似性,下载和过滤 CommonCrawl 数据集;在数据集中执行在文档级别模糊重复数据删除,防止冗余,并保持验证集的完整性;添加已知的高质量参考语料库(GPT-2 的 WebText 数据集、基于互联网的图书语料库 Books1 和 Books2 和英文维基百科)训练混合增广 CommonCrawl 数据集和增加其多样性。
- (我觉得有意义的)重点介绍了数据集的清洗,验证模型是真正 “应用” 还是仅仅基于对过去的 “记忆” 。
文章目录
- Language Models are Few-Shot Learners
- B 部分
- 7. Broader Impacts
- 7.1 Misuse of Language Models
- 7.1.1 Potential Misuse Applications
- 7.1.2 Threat Actor Analysis
- 7.1.3 External Incentive Structures
- 7.2 Fairness, Bias, and Representation
- 7.2.1 Gender
- 7.2.2 Race
- 7.2.3 Religion
- 7.2.4 Future Bias and Fairness Challenges
- 7.3 Energy Usage
- 7.4 News Generation
- 附录 E Human Quality Assessment of Synthetic News Articles
7. Broader Impacts
语言模型对社会有广泛的有益应用,包括代码编写自动完成、语法辅助、生成游戏解说、改进搜索引擎的响应和回答问题。但它们也有潜在的有害应用。 GPT-3 提高了文本生成的质量,增加了区分合成文本和人工书写文本的难度。
7.1 Misuse of Language Models
7.1.1 Potential Misuse Applications
随着文本合成质量的提高,语言模型的误用潜力不断增加。GPT-3 能够生成几段人们认为难以与人工书写的文本区分的合成内容,这是一个令人担忧的事。
7.1.2 Threat Actor Analysis
威胁行为者(Threat Actor)可以按技能和资源水平进行组织,范围从:可能能够构建恶意产品的低技能或中等技能且资源丰富的行为者,到 “高级持续威胁” (Advanced Persistent Threats, APTs):高技能和资源充足(例如长期国家资助的)团体。
为了理解低技能和中等技能的行为者如何看待语言模型,作者一直在监控那些经常讨论错误信息策略、恶意软件分发和计算机欺诈的论坛和聊天群组。虽然作者确实发现了在 2019 年春季首次发布 GPT-2 之后关于滥用的重要讨论,但自那以后作者发现实验的例子较少,且没有成功的部署。此外,这些滥用讨论与媒体对语言模型技术的报道相关联。由此,作者评估这些行为者滥用的威胁并不是立即的,但可靠性的显著提高可能会改变这一点。
因为高级持续威胁(APTs)通常不会公开讨论其操作,作者咨询了专业的威胁分析师关于可能涉及使用语言模型的高级持续威胁的活动。评估认为,语言模型可能不值得投入大量资源,因为没有令人信服的证据表明当前的语言模型比现有的文本生成方法有显著的优势,而且针对 “定向” 或 “控制” 语言模型内容的方法仍处于非常初级的阶段(2020年)。
7.1.3 External Incentive Structures
每个威胁行为者群组都有一套他们依赖的战术、技术和程序(Tactics, Techniques, Procedures, TTPs)来实现他们的目标。这些 TTPs 受到诸如可扩展性和部署难易度等经济因素的影响。网络钓鱼在所有群组中都非常流行,因为它提供了一种低成本、低付出、高收益的部署恶意软件和盗取登录凭证的方法。使用语言模型来增强现有的 TTPs 可能会导致部署成本进一步降低。
易用性是另一个重要的动机。拥有稳定的基础设施对 TTPs 的实现有很大影响。但是,语言模型的输出是随机的,尽管开发者可以对其加以约束(如使用 top-k 截断),但在没有人类反馈的情况下,他们无法保持一致的性能。如果一个社交媒体虚假信息机器人的输出可靠性为 99 % \% % ,但 1 % \% % 的时候产生不连贯的输出,这可能会减少操作此机器人所需的人工劳动。但仍需要人工对输出进行过滤,这限制了操作的可扩展性。
作者希望通过缓解研究、原型开发和与其他技术开发者协调配合的方式来应对这一问题。
7.2 Fairness, Bias, and Representation
训练数据中存在的偏差可能会导致模型生成具有成见或偏见的内容。模型偏见可能会通过强化现有的生成内容和产生贬低性的描述等方式,对相关群体造成伤害,这令人担忧。作者已经对模型中的偏见进行了分析,以更好地了解 GPT-3 在公平性、偏见和代表性方面的局限性。分析表明,使用网络文本训练的模型存在网络规模的偏差;模型往往反映了训练数据中存在的刻板印象。
7.2.1 Gender
在对 GPT-3 中性别偏见的调查中,作者重点关注了性别与职业之间的关联。在给定诸如 “这个 {职业} 是一个...” (以及这个句子的中性同义变换)的上下文时,总的来说,职业更有可能被后接男性性别标识符而不是女性。作者测试的 388 个职业中,有 83
%
\%
% 更有可能被 GPT-3 后接男性标识符。
测量方式是,给模型提供一个诸如 “这个侦探是一个...” 的上下文,然后观察模型后接男性表述(如:男人、男性等)还是女性表述(如:女人、女性等)的概率。特别是,那些需要较高教育水平的职业,如:立法者、银行家或教授,以及需要体力劳动的职业,如:砌砖工、轧轧工和警长,都更倾向于男性。而产妇看护人、护士、接待员、管家等职业更倾向于被后接女性标识符。
作者还测试了在不同的上下文中这些概率发生的变化。当我们将上下文改为 ”这个有能力的 {职业} 是一个...“ (以及其他变体表述)时,以及将上下文改为 ”这个无能的 {职业} 是一个...“ (以及其他变体表述)时,对于数据集中的每个职业进行了测试。
当提示为 ”这个有能力的 {职业} 是一个...“ 时,大多数职业被后接男性标识符的概率比使用最初的中性提示 “这个 {职业} 是一个...” 时更高。而使用提示 ”这个无能的 {职业} 是一个...“ 时,大多数职业仍然倾向于男性,概率与最初的中性提示相似。
衡量标准是:
B
=
1
n
j
o
b
s
∑
n
j
o
b
s
log
P
(
f
e
m
a
l
e
∣
c
o
n
t
e
x
t
)
P
(
m
a
l
e
∣
c
o
n
t
e
x
t
)
B = \frac{1}{n_{jobs}}\sum_{n_{jobs}}\log\frac{P(female|context)}{P(male|context)}
B=njobs1njobs∑logP(male∣context)P(female∣context)
作者还使用两种方法对 Winogender 数据集进行了代词消解,进一步证实了该模型倾向于将大多数职业与男性联系在一起的倾向。
一种方法是测量模型正确指定代词为职业还是参与者的能力。例如,向模型提供了这样的上下文:“顾问会见了被咨询者,因为她想就工作申请寻求建议。‘她’ 指的是哪一方?” 在两个可能的选项(职业选项:顾问;参与者选项:被咨询者)之间找到概率最低的选项。
职业和参与者的词汇通常会带有社会偏见,比如默认认为大多数从业者都是男性。作者发现,语言模型学习到了一些这样的偏见:比如倾向于将女性代词与参与者角色联系在一起,而不是男性代词。 GPT-3 175B 在这项任务上的准确度最高(64.17 % \% %)。其他所有模型在职业句子中都表现出男性代词的准确度更高,除了我们第二大的模型 GPT-3 13B 。这提供了一些初步证据,即在容易受到偏见影响的问题领域,较大的模型比较小的模型更加稳健。

还进行了共现测试。分析了某些预选词与其他词在文本中出现的可能性。作者创建了一个模型输出样本集,对数据集中的每个提示,生成 800 个长度为 50 的输出,温度设为 1 , top-p 设为 0.9 。对于性别,有诸如 ”他/她非常…“ 、 ”他/她会被描述为…“ 等提示。作者使用现成的词性标注器,检查了 100 个最常出现的词中的形容词和副词。作者发现,与描述男性时更广泛使用形容词相比,描述女性时更常使用与外表相关的词语,如 ”漂亮“ 和 ”迷人“ 。
7.2.2 Race
为了调查 GPT-3 中的种族偏见,使用诸如 “那个 {种族} 男人非常...” 、 “那个 {种族} 女人非常...” 和 “人们会将 {种族} 描述为...” 等提示启动了模型,并为每个提示生成了 800 个样本,其中 {种族} 被替换为诸如 “白人” 或 “亚洲人” 等种族术语。然后测量了生成样本中词语的共现情况。
鉴于先前的研究表明,语言模型在改变职业等特征时会产生不同情感的文本。作者探讨了种族如何影响情感。使用 SentiWordNet 测量了每种种族词汇的情感得分。得分在 100 到 -100 之间,正分表示积极词汇(如 wonderfulness: 100 , amicable: 87.5),负分表示消极词汇(wretched: -87.5 , horrid: -87.5),0 表示中性词汇(如 sloping , chalet)。
需要注意的是,明确地要求模型谈论种族,这导致生成的文本集中在种族特征上;这些结果不是模型在自然环境下谈论种族,而是在实验设置中被要求这么做。此外,由于仅通过词共现来测量情感,结果可能反映了社会历史因素 。例如,与奴隶制有关的文本通常会有负面情感,这可能导致某个人口群体在此测试方法下与负面情感相关。
在作者分析的所有模型中,“亚洲人” 一直有很高的正面情感,在 7 个模型中排名第 1 。相比之下,“黑人” 一直有很低的负面情感,在 7 个模型中排最低。这种差异随着模型规模的增大而有所缩小。这一分析揭示了不同模型的偏见,并突出了需要更复杂的分析来理解情感、实体及输入数据之间的关系。
7.2.3 Religion
作者研究了哪些词与与无神论、佛教、基督教、印度教、伊斯兰教和犹太教有关的宗教术语的提示词同时出现,通过生成 800 个模型输出,温度为 1 ,top-k 为 0.9 。提示词是 "{Religion practitioners} are..." 。
与种族偏见类似,作者发现这些模型也在某种程度上反映了宗教术语在现实世界中的呈现方式。例如,对于伊斯兰教,作者发现诸如 “斋月” 、“先知” 和 “清真寺” 等词语的共现频率高于其他宗教。作者还发现,诸如 “暴力” 、 “恐怖主义” 和 “恐怖分子” 等词语与伊斯兰教的共现频率高于其他宗教,并在 GPT-3 中位列伊斯兰教相关词语的前 40 名。
7.2.4 Future Bias and Fairness Challenges
为了为通用模型中有效的预防偏见铺平道路,有必要建立一个共同的词汇,将这些模型中减轻偏见的规范、技术和经验挑战结合在一起。还有更多的研究空间,涉及 NLP 之外的文献,更好地阐明关于伤害的规范陈述,并涉及受 NLP 系统影响的社区的生活经验。缓解语言模型的偏见性工作不应该纯粹以一个度量驱动的目标来 “消除” 偏见,因为这已经有文献被证明有盲点,而是需要以一种整体的方式在缓解。所以 OpenAI 后面的措施就是建立了一个敏感词词库,当模型输出的 token 在敏感词里面的时候,就会提前报错,提高了安全性。
7.3 Energy Usage

Training the GPT-3 175B consumed several thousand petaflop/s-days of compute during pre-training, compared to tens of petaflop/s-days for a 1.5B parameter GPT-2 model.
大规模预训练语言模型的使用也对大型模型的效率展开了一个新的视角——不仅应该考虑训练投入的资源,还需要考虑这些资源如何在模型训练中摊销,以及将语言模型用于各种目的和微调特定的任务的消耗。
尽管像 GPT-3 这样的模型在训练过程中消耗了大量资源,但一旦经过训练,它们可以惊人地高效:即使使用完整的 GPT-3 175B 生成 100 页的内容的成本可能在 0.4 kW-hr 左右,或者只有几美分的能源成本。
此外,像模型蒸馏这样的技术可以进一步降低此类模型的成本,让头部机构采用训练单一、大规模模型的范式,然后创建更有效的版本,以便在适当的上下文中使用。随着时间的推移,算法的进展也可能自然会进一步提高此类模型的效率,类似于在图像识别和神经机器翻译中观察到的趋势。
7.4 News Generation
作者测试 GPT-3 生成合成性的 “新闻文章” 的能力,通过使用之前的三篇新闻文章的上下文以及建议生成的文章的标题和副标题来提示模型。为了衡量生成的文章的质量,作者测量了人类区分 GPT-3 生成的文章和真实的文章的能力。生成式语言模型用人类生成的内容的分布相同的分布训练,因此人类区分两者的能力是一个潜在的重要的质量衡量标准。
为了了解人类检测模型生成的文本的能力,作者任意选择了网站上的 25 个文章标题和副标题(平均长度: 215 个词)。然后,作者为从 125M 到 175B 参数的语言模型生成了这些标题和副标题的补充内容(平均长度: 200 个词)。对于每一个模型,作者向大约 80 名美国参与者展示了一个包含这些真实标题和副标题以及人类撰写或模型生成文章的测验。参与者被要求选择该文章 ”很可能是由人类撰写的“ 、”更可能是由人类撰写的“ 、”我不知道“ 、 ”更可能是由机器撰写的“ 或 ”很可能是由机器撰写的“ 。
所选文章并不在模型的训练数据中,模型输出经过格式化和编程选择,以防止人为挑选。所有模型使用相同的上下文来生成输出,并且都使用相同大小的语料进行预训练,同时用于每个模型的文章标题和副标题也是相同的。然而,作者还进行了一个实验来控制参与者的注意力,该实验遵循相同的格式,但涉及故意生成的劣质模型文章。这是通过从一个 ”对照模型“ (一个 160M 参数模型,没有上下文,输出随机性增加)生成文章来实现的。

参与者准确地识别出故意生成的劣质文章是模型生成的的平均准确率约为 86 % \% % ,而随机水平为 50 % \% % 。相比之下,参与者准确地识别出由 175B 参数模型生成的文章的平均准确率仅略高于随机水平,约为 52 % \% % (见表7.3)。人类检测模型生成文本的能力似乎随着模型规模的增加而降低:准确率呈现向随机水平靠拢的趋势,人类对 GPT-3 的检测接近于随机水平(尽管参与者在处理较大模型输出时花费的时间更长)。
事实性错误可以作为文章是模型生成的一个指标,因为不像人类作者,模型无法访问文章标题提及的特定事实或文章撰写时的时间。其他指标包括重复、非逻辑性和不寻常的措辞,尽管这些通常较为微妙,不太容易被注意到。
Ippolito等人对语言模型检测的相关工作表明, GROVER 和 GLTR 等自动鉴别器在检测模型生成的文本方面可能比人类评估者有更大的成功。这些模型的自动检测可能是未来研究的一个很有前途的领域。
Ippolito 等人还指出,当人类观察更多的 token 时,人类检测模型生成文本的准确性会提高。为了初步研究人类在检测 GPT-3 175B 生成的更长新闻文章方面的能力,作者从路透社选择了 12 篇世界新闻文章,平均长度为 569 个单词,并使用 GPT-3 生成了这些文章的补充内容,平均长度为 498 个单词(比我们初始实验中的长度长 298 个单词)。遵循上述方法,作者进行了两个实验,每个实验都有大约 80 名美国参与者,以比较人类检测由 GPT-3 和对照模型生成的文章的能力。

作者发现,参与者准确地识别出对照模型生成的故意劣质较长文章的平均准确率约为 88 % \% % ,而准确地识别 GPT-3 175B 生成的较长文章的平均准确率仍然略高于随机水平,约为 52 % \% % 。这表明,对于长度约为 500 个单词的新闻文章,GPT-3 仍然能生成人类难以区分于人类撰写新闻文章的内容。

人们识别新闻文章是否由模型生成(由正确分配与非中性分配的比例来衡量)的能力随着模型规模的增加而降低。故意破坏的控制模型(一个非条件的输出随机性较高的 GPT-3 小模型)的输出精度用顶部的虚线表示,随机概率(50 % \% %)用底部的虚线表示。最佳拟合线是具有 95 % \% % 置信区间的幂律。
附录 E Human Quality Assessment of Synthetic News Articles
本附录提供了测量人类区分 GPT-3 生成的合成新闻文章和真实新闻文章能力的实验细节。作者首先描述了针对约 200 字新闻文章的实验,然后描述了对 GPT-3 生成约 500 字新闻文章的初步调查。
作者招募了 718 名独特参与者参加 6 个实验。97 名参与者因未通过互联网检查问题而被排除,剩余 621 名参与者: 343 名男性、 271 名女性和 7 名其他性别。参与者平均年龄约为 38 岁。所有参与者都是通过 Positly 招募的: Positly 维护了一个 Mechanical Turk 上高绩效工作者的白名单。所有参与者都是美国人,但没有其他人口统计限制。参与者获得 12 美元的报酬,根据试运行确定的任务时间估计为 60 分钟。为确保每个实验测验的参与者样本是唯一的,参与者不允许参加同一实验多次。
作者任意选择了 2020 年初出现在网站上的 25 篇新闻文章。作者使用这些文章的标题和副标题,从 125M 、 350M 、 760M 、 1.3B 、 2.7B 、 6.7B 、 13.0B 和 200B 参数语言模型中生成输出。每个模型每个问题生成 5 个输出,自动选择最接近人类撰写文章长度的生成内容。这是为了最小化完成长度对参与者判断的影响。除了去除了主文中描述的故意劣质对照模型之外,每个模型的输出过程都是相同的。
在每个实验中,一半参与者被随机分配到测验 A ,另一半被随机分配到测验 B 。每个测验都包含 25 篇文章:一半(12-13 篇)是人类撰写的;另一半(12-13 篇)是模型生成的:测验 A 中有人类撰写完成的文章,在测验 B 中有模型生成的完成内容,反之亦然。每个参与者的测验题目顺序都是随机打乱的。参与者可以留下评论,并被要求指出他们是否之前见过这些文章。参与者被指示在测验期间不要查找文章或其内容,测验结束时被问是否在测验过程中查找了任何内容。
为了比较不同运行的平均值,对每个模型与对照组进行了两个独立样本的 t 检验。这是使用 Python 中的 scipy.stats.ttest_ind 函数实现的。在绘制参与者平均准确率与模型规模的回归线时,作者拟合了线性形式的幂律函数。95
%
\%
% 的置信区间是从样本均值的 t 分布估计出来的。
在正文中,作者讨论了一个发现,即人类参与者区分模型生成和人类生成新闻文章的能力随着模型规模的增大而降低。正如图所示,参与者花在一组给定问题上的平均时间随着模型规模的增大而增加。尽管参与者投入了更多时间,但准确度仍然较低,这支持了更大模型生成的新闻文章更难区分的发现。

参与者花更多时间来试图确定每一篇新闻文章是否都是随着模型大小的增加而由机器生成的。控制模型上的持续时间用虚线表示。最佳拟合线是一个具有 95 % \% % 置信区间的对数尺度上的线性模型。

作者通过 Positly 招募了 160 名独特的美国参与者参加 2 个实验。作者随机选择了 2019 年末的 12 篇路透社世界新闻文章,并为 GPT-3 175B 创建了一个上下文,由一篇不在这 12 篇中的路透社文章组成。然后,作者使用这些文章的标题和路透社位置信息,从 GPT-3 175B 和前述实验中的 160M 对照模型生成补充内容。这些内容被用来创建每个模型 2 个 12 题测验,每个测验由一半人类撰写和一半模型生成的文章组成。作者添加了理解问题,并以 30 秒的间隔分 3 个阶段向参与者展示文章,以鼓励他们仔细阅读。参与者获得 12 美元的报酬。
模型生成选择方法、排除标准和统计检验与先前的实验保持一致。